YumeLog:我写的高颜值个性化主页系统
|2 个月前
最近我把自己的个人主页系统整理并开源了,项目名字叫做 yumeLog(ユメログ)。项目已经支持全页面SEO(BASE: VITE-SSG),每次编译你都可以将你所有博客文章生成专为robot提供的 index.html 。经过测试telegram/QQ/Google都能正确识别并生成卡片。 一个编译后连代码高亮js部分只有1M的极简主页/博客系统项目基于 Vue3 + TypeScript + NaiveUI开发,目标不是做传统博客,而是做一个更像“个人数字名片”的网站。GitHub 地址:点我查看项目仓库
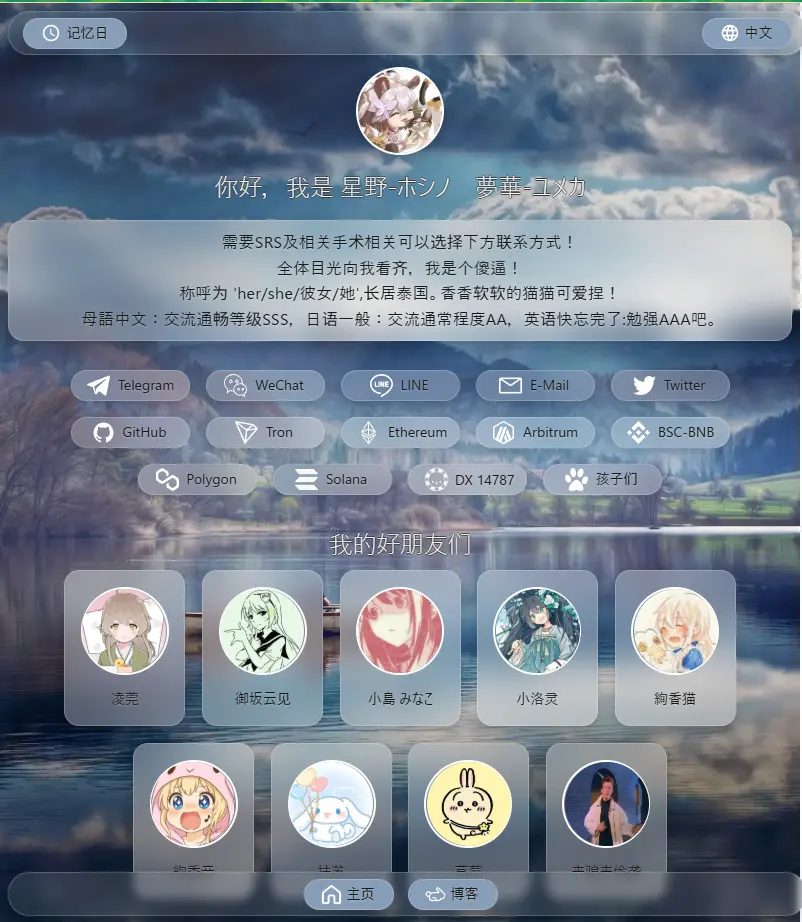
yumeLog Home 桌面端预览

yumeLog Home 移动端预览
为什么写这个项目?为什么不用通用解决方案捏:不符合我胃口,UI设计不喜欢。其次是比较重,大多需要后端,部署复杂,维护火葬场,我的vps就300G月流量要干很多事情。以及个人信息展示能力很弱。所以我干脆自己写了一:一个完全静态的个人主页 + 博客。没有后端,没有数据库,只需要托管静态文件即可运行。担心国内被劫持访问不了?没关系支持热备。
核心技术特点自研文本解析引擎:项目没有使用 Markdown,而是自己写了一套轻量级解析器。支持:bold underline strike center link thin code info warning 。而且支持 无限嵌套。你可以使用- type: "divider"为文本进行分段,也可以用- type: "image"为文章添加图片和描述。
点我进查看语法示例
完整示例yumeDSL
@meta
layout: common
time: 20260316
lang: zh
id: bangkok-life
pin: true
title: 曼谷的午后喵
summary: 这是一篇用于演示 yumeDSL 语法结构的文章
cover: /data/blog/img/post3/home-laptop.webp
@end
@text
欢迎来到 $$bold(yumeDSL)$$ 示例。
它支持 $$underline(嵌套 inline)$$、$$link(https://example.com | 链接)$$、$$thin(弱强调)$$ 与 $$code(code tag)$$。
$$center($$bold(这是一个中心对齐的嵌套示例)$$)$$
$$info(提示标题 | 这一段是 inline titled block,支持标题与正文分离)$$
$$warning(注意事项)%
这是一段 raw 形态的 warning。
它会保留原始换行,并且支持像 %end$$ 这样的转义闭合符。
%end$$
$$collapse(点我展开查看块级正文)*
这里是 block 形态的 collapse。
你可以在正文里继续写 $$bold(嵌套 rich text)$$。
也可以继续写 $$info(块内提示 | 支持继续解析 inline)$$。
如果你想在 block 正文里直接写闭合符本身,可以写成 \*end$$,它不会提前闭合当前块。
*end$$
$$raw-code(json | demo.json | JSON 示例)%
{
"hello": "world",
"nested": true
}
%end$$
@end
@image
- src: https://example.com/cover.webp
spareUrl: /data/blog/img/post3/home-laptop.webp
alt: 曼谷街景
desc: "I \"love\" Bangkok"
- src: https://example.com/cat.webp
spareUrl: /data/blog/img/post3/blog-phone.webp
desc: |
这是多行支持
123
这里仍然属于同一个字段
- src: https://example.com/night.webp
desc: 请注意这是完全缩进语言
@end
@divider
@end
@text
\@image --> @image
\\@image --> \@image
\\\@image --> \\@image
\@end --> @end
- inline-close: \)$$ --> )$$
- raw-close: %end$$ --> %end$$
- block-close: \*end$$ --> *end$$
- desc: "I \"love\" BKK" --> I "love" BKK
- path: "C:\\\\Users" --> C:\\Users
- mixed: "\\\\\\" " --> \\"
$$bold(很好)$$
$$info(正常示例 | 这一块标题和正文都合法)$$
$$link(https://github.com/chiba233/YumeLog | $$bold(链接正文也能继续嵌套)$$)$$
@end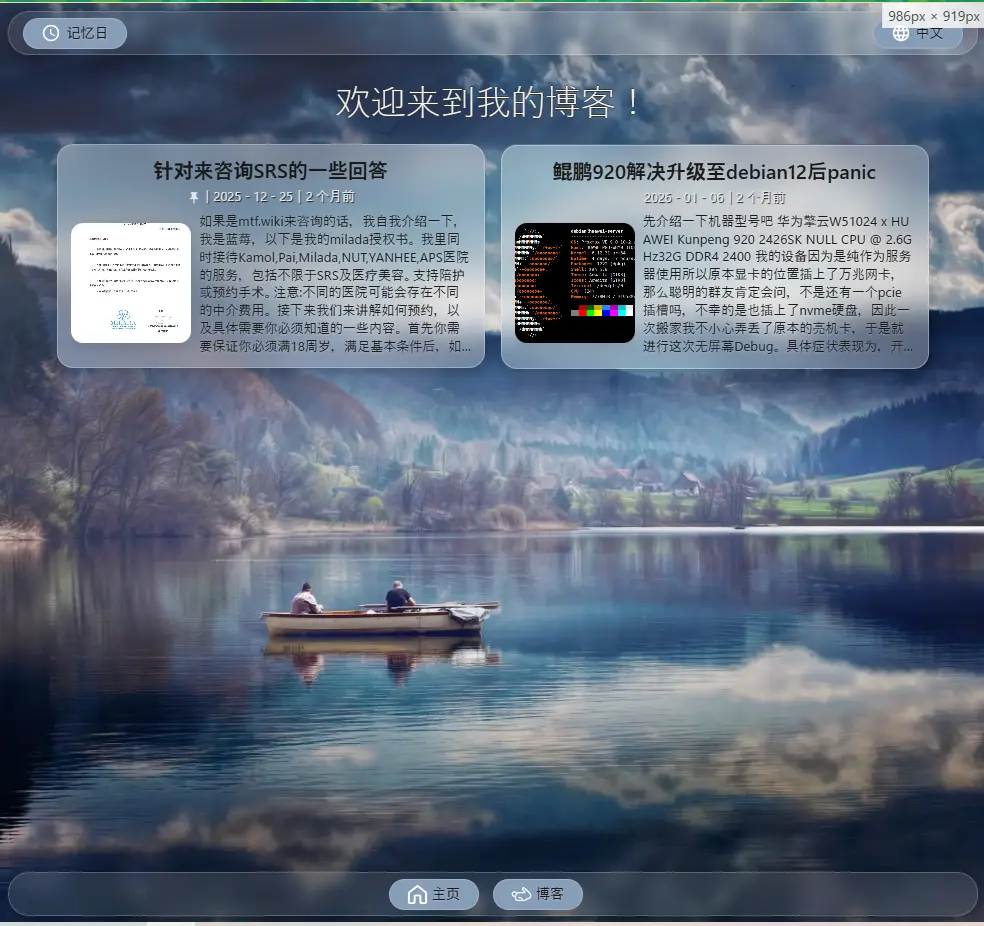
yumeLog Blog 桌面端预览

yumeLog Blog 移动端预览
YAML 内容驱动:博客文章全部使用 YAML 编写,例如:id / time / title / blocks,每个文章由多个 block组成。支持:文本块 图片块 多图片展示。因为是纯数据驱动,所以:不需要数据库,也不需要后端
完全静态架构:所有数据都来自仓库文件:YAML JSON 图片资源,所以部署非常简单:GitHub Pages Cloudflare Pages Vercel Nginx都可以直接部署。
点我进查看url配置示例
url配置示例json
{
"blog": {
"listUrl": "https://YOUR-LIST_URL",
"url": "https://YOUR_URL",
"spareUrl": "/YOUR_SPARE-URL",
"spareListUrl": "/YOUR_SPARE_LIST_URL"
},
"main": {
"url": "这里主要是你个人简介那堆东西的地址,就是在/public/data/main里的那堆东西,你当然也可以远程,但是丢服务器就行了",
"spareUrl": "/YOUR_SPARE-URL",
"listUrl": "/YOUR_SPARE_LIST_URL"
}
}个人主页模块:除了博客系统之外,yumeLog 还包含完整的个人展示模块:主题系统 多语言支持 纪念日时间线 友链展示 联系方式 照片墙,本质上它更像是:一个完整的个人网站框架全融合的主题: yumelog本身会使用你在json内配置的主题色来生成: 浅色及加深色供不同区域使用以增强美观度或可读性。 友链展示说明:socialLinks内每个都可以删掉,删掉后ui会自动取消渲染该内容。platforms里面正常情况下你不需要动。 From Now Time 模块: list.json配置: 请注意,这必须是数组!
点我进查看友链配置示例
友链展示json
{
"socialLinks": {
"twitter": "https://x.com/HoshinoYumeka2",
"tron": "https://tronscan.org/#/address/TVB16jV3Jx2HTn9U1KjyBSN1u9MQ29FArs",
"areth": "https://arbiscan.io/address/0x3eb232c80307961795C1310374368834c25A41e6",
"eth": "https://etherscan.io/address/0x3eb232c80307961795C1310374368834c25A41e6",
"polygon": "https://polygonscan.com/address/0x3eb232c80307961795C1310374368834c25A41e6",
"bsc": "https://bscscan.com/address/0x3eb232c80307961795C1310374368834c25A41e6",
"solana": "https://solscan.io/account/CwmEwePc5TxyQG57e3f4WBufTvGFv264KAGfVRoSZd7V",
"telegram": "https://t.me/chiba2333",
"email": "mailto:qwq@qwwq@org",
"github": "https://github.com/chiba233"
},
"platforms": [
{
"id": "telegram",
"label": "Telegram",
"type": "link"
},
{
"id": "wechat",
"label": "WeChat",
"type": "modal"
},
{
"id": "line",
"label": "LINE",
"type": "modal"
},
{
"id": "email",
"label": "E-Mail",
"type": "link"
},
{
"id": "twitter",
"label": "Twitter",
"type": "link"
},
{
"id": "github",
"label": "GitHub",
"type": "link"
},
{
"id": "tron",
"label": "Tron",
"type": "link"
},
{
"id": "eth",
"label": "Ethereum",
"type": "link"
},
{
"id": "areth",
"label": "Arbitrum",
"type": "link"
},
{
"id": "bsc",
"label": "BSC-BNB",
"type": "link"
},
{
"id": "polygon",
"label": "Polygon",
"type": "link"
},
{
"id": "solana",
"label": "Solana",
"type": "link"
},
{
"id": "maimai",
"label": "maimai",
"type": "func"
},
{
"id": "cat",
"label": "cat",
"type": "func"
}
]
}点我进查看From Now Time 模块配置示例
fromNowyaml
fromNow: #起始块不能删
- time: "20161225" #时间
photo: "" #预留 还没做
names:
- type: "zh"
content: "你好"
- type: "en"
content: "Hello!"
- type: "ja"
content: "天気がいいから、散歩しましょう"
- type: "other"
content: "Hello!"
#请注意,自己的东西都得自己翻译点我进查看list.json配置示例
list.jsonjson
[
"post1.yaml",
"post2.yaml",
"post3.yaml"
]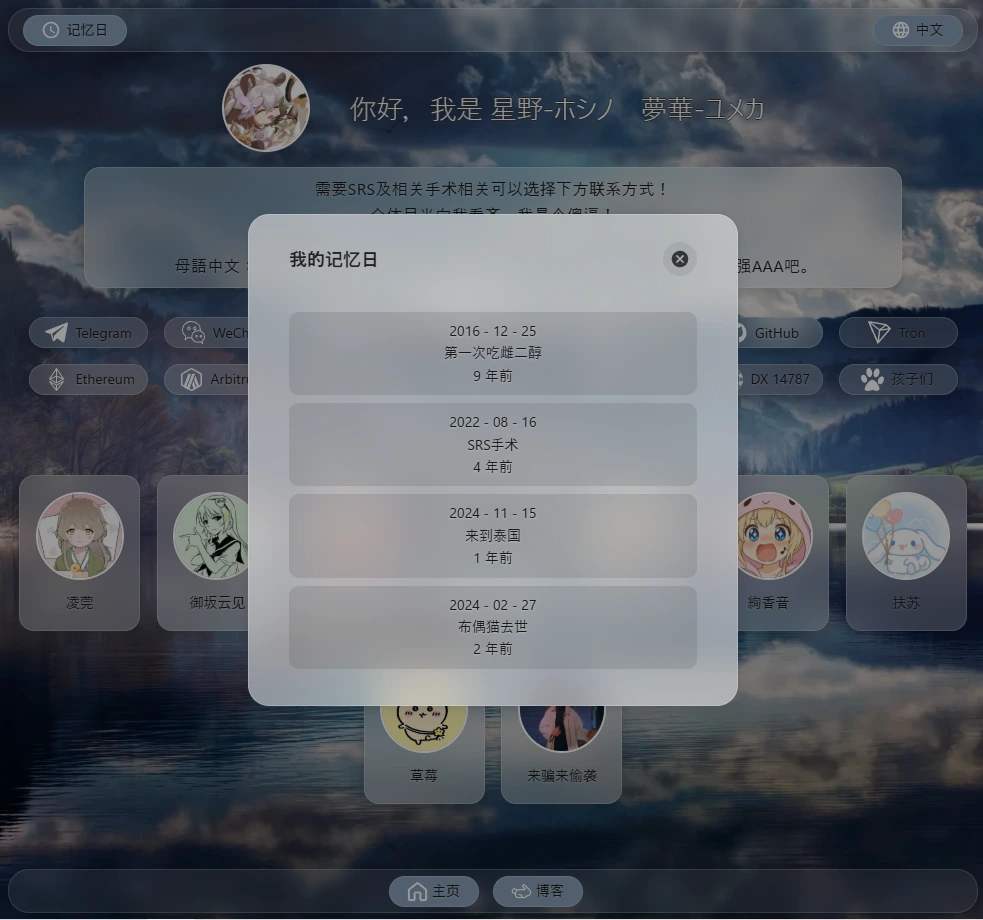
纪念日预览
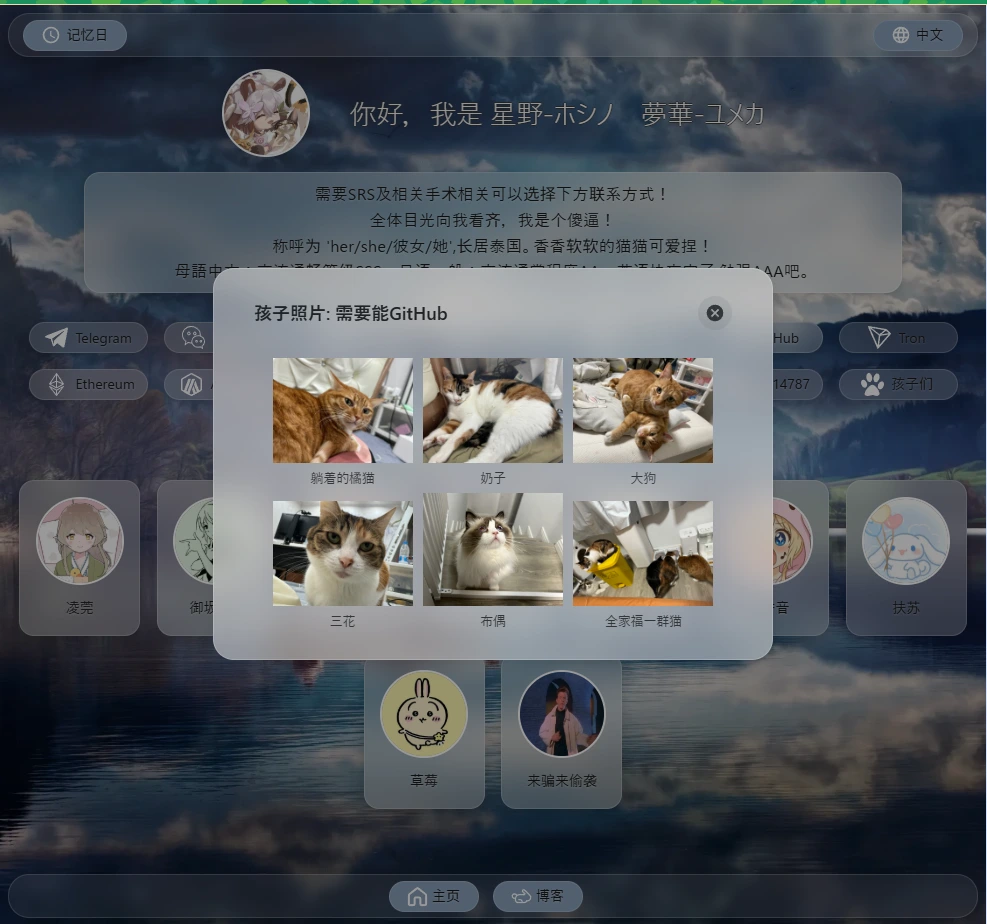
照片展示墙预览
Maimai 玩家模块:如果你是WMC,这个功能会非常有意思。项目原生支持:Maimai DX 成绩展示可以在主页直接展示你的:段位 Rating 成绩列表,数据来自 Aqua 服务器 API。
点我进查看maimai配置文件示例
maimai配置文件json
{
"baseUrl": "aqua.server.com",
"aimeID": "1145141919810"
}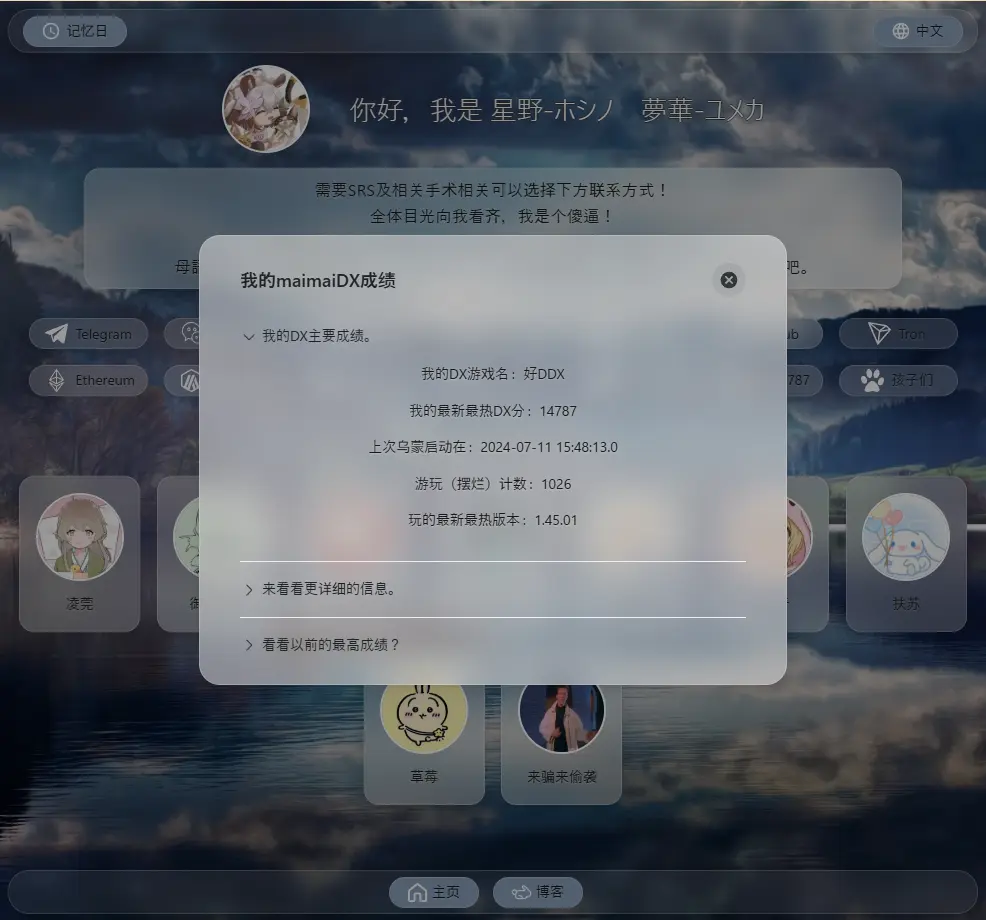
maimai成绩展示预览